Key characteristics of GraphQL
In a nutshell, GraphQL is all about optimizing data communication between a client and a server. This includes the client asking for needed data and communicating that need to the server, and the server preparing a fulfillment for that need and communicating the fulfillment back to the client. GraphQL allows clients to ask for the exact data they need and makes it easier for servers to aggregate data from multiple data storage resources.
- GraphQL is a query language from which you can build APIs. It exists as an abstraction layer between a client that issues requests and a backend comprising any number of databases that responds to queries.
- Crucially, with applications that utilise GraphQL, both the backend and the frontend use the same GraphQL syntax. They speak the same language. This means that neither needs to take account of the way in which the other is implemented. For example, a client could request data from both a relational database and an object database without knowing there is any difference from its point of view. Conversely, client requests could be made through JavaScript or Python and the structure of the request received by the backend would be the same.
- The main benefit is its interoperability and its network economy when compared to REST APIs: you ask only for what you want and you get only that; there is no surplus data, increasing efficiency, reducing the number of network requests and reducing the size of the payload.
The best way to think of GraphQL architecturally is to think of it as a different technique for instantiating the uniform interface, client/server decoupling, and layered-system architecture contraints of traditional REST APIs. However, instead of making GET or POST requests to a REST endpoint URL and passing parameters, you send a structured query object.
Architecture
From the point of view of the frontend, GraphQL is a query language that may be used via wrappers for a given framework or programming language (such as Apollo) or directly simply by sending requests over HTTPS to a single URL.
From the point of view of the backend, GraphQL is a runtime that provides a structure for servers to describe the data to be exposed in their APIs. We call this structure the schema. For example, the GraphQL server might translate the query into SQL statements for a relational database then take what the storage engine responds with, translate it into JSON and send it back to the client application.
The backend implementation of GraphQL is known as the GraphQL server. This server is distinct from any of the physical servers that the backend may rely on. The client queries the GraphQL server.
Client requests are sent over HTTPS and the data is typically returned in the form of JSON:
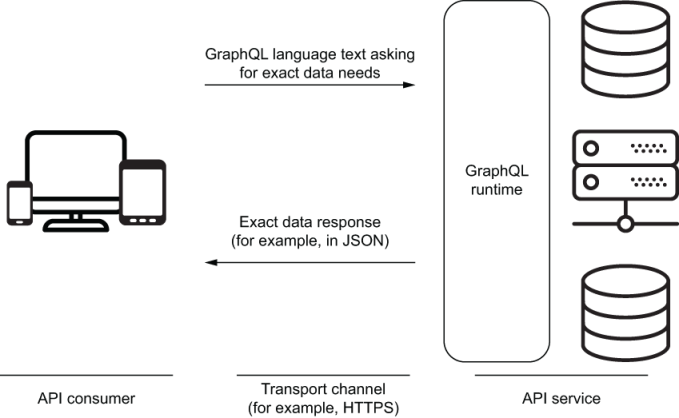
Implementation overview
Queries, mutations, subscriptions
Queries can be used for both reading and modifying data.
- When you need to read data with GraphQL you use queries
- When you need to modify data, you use mutations
So, for comparison, a query would be akin to a READ instruction in SQL or a GET request send to a REST API. A mutation would be akin to WRITE then READ instruction in SQL or a POST request to a REST API.
There is a third request type called a subscription. This is used for real-time data monitoring requests, like a data stream, similar to a continuous READ process. Mutations typically trigger events that can be subscribed to.
Frontend
Below is an example of a request that would be made to a GraphQL server from the frontend:
query {
employee(id: 42) {
name
email
}
}Backend: structure and behaviour
We define the structure of a GraphQL API on the backend through the schema. A schema is strongly typed and is basically a graph of fields that have types, e.g
type Employee(id: Int!) {
name: String!
email: String!
}! stands for required. In addition to the standard primitive data-types you can also have custom types.
We implement the behaviour of the API through functions called resolver functions. Each field in a GraphQL schema is backed by a resolver function. A resolver function defines what data to fetch for its field.
A resolver function represents the instructions on how and where to access raw data. For example, a resolver function might issue a SQL statement to a relational database, read a file’s data directly from the operating system, or update some cached data in a document database. A resolver function is directly related to a field in a GraphQL request, and it can represent a single primitive value, an object, or a list of values or objects.
GraphQL endpoint
The GraphQL server exposes a single endpoint as a URL. This is in contrast to a REST API where there are multiple endpoints, each corresponding to a different resource. With GraphQL, the request is not specified by the URL and the payload but rather in the GraphQL string that you send to the endpoint, like the employee query above.
Benefits
Single requests
With a REST API if you require multiple resources you have to make multiple requests to different endpoints and then once they resolve, synthesise them on the client side. With GraphQL you can send a single request that encompasses each individual resource:
The REST scenario:

The GraphQL scenario:

Abstraction of multiple services
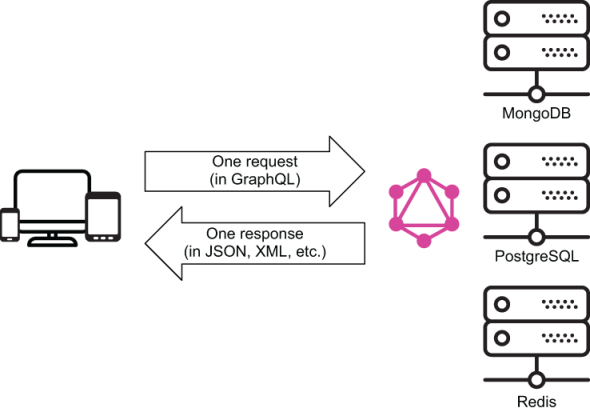
Stops overfetching
In a strict REST API you must request all resources from a given resource and then filter on the client. With GraphQL you request only the resource you need at the client-level.
Single endpoint
In GraphQL you have a single endpoint and it always remains the same. This makes updates easier to manage, since you don’t need to broadcast new endpoints as the API grows. It also simplifies frontend parsing, since you don’t need to account for, or interpolate different endpoints in your request URL.
