DynamoDB
Data structure
Non-relational tables
DynamoDB is “NoSQL” because it does not support #SQL queries and is non-relational meaning there cannot be JOIN operations via foreign_keys
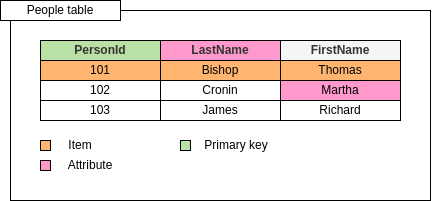
Primary key
Although the data is stored as a table, one of the attributes is a primary key and the rest of the attributes are effectively the “value” associated with it.
Because DynamoDB is schemaless, other than the primary key, neither the attributes or their data types need to be defined beforehand and each item can have its own distinct attributes.
Each item in the table is uniquely identifiable by its primary key.
There are two types of primary key available:
partition key: a simple primary key composed of one attribute only. Because the primary key is hash-mapped items can be retrieved very rapidly using the primary key. This would be the
personIdalone.composite key: this comprises a partition key and a sort key both of which are attributes. In a table that has a partition key and a sort key, it’s possible for multiple items to have the same partition key value. However, those items must have different sort key values. You could then query by either key or both. For instance using the
PersonIdalong withLastName
Secondary index
As well as the index provided by the primary key, you can set one or more secondary indices. A secondary index lets you query the data in the table using an alternate key.
A global secondary index is useful for querying data that needs to be accessed using non-primary key attributes. For example, if you have a Users table with UserID as the primary key but often need to fetch users by their Email, a GSI on Email would be appropriate.
There are also local secondary indices but I don’t understand the difference.
Real example
Below is a specification of the DynamoDB table I am using for my time-entries project:
{
"TableName": "TimeEntries",
"KeyAttributes": {
"PartitionKey": {
"AttributeName": "activity_start_end",
"AttributeType": "S"
}
},
"NonKeyAttributes": [
{
"AttributeName": "activity_type",
"AttributeType": "S"
},
{
"AttributeName": "start",
"AttributeType": "S"
},
{
"AttributeName": "end",
"AttributeType": "S"
},
{
"AttributeName": "duration",
"AttributeType": "N"
},
{
"AttributeName": "description",
"AttributeType": "S"
},
{
"AttributeName": "year",
"AttributeType": "S"
}
],
"GlobalSecondaryIndexes": [
{
"IndexName": "YearIndex",
"KeyAttributes": {
"PartitionKey": {
"AttributeName": "year",
"AttributeType": "S"
},
"SortKey": {
"AttributeName": "start",
"AttributeType": "S"
}
},
"Projection": {
"ProjectionType": "ALL"
}
}
]
}This defines the attribute activity_start_end as the primary key. This string (S) value is a concatenation of three attributes, which is a way of ensuring each entry for the attribute will be unique.
The NonKeyAttributes are all the other attributes in addition to the primary key. As mentioned these do not actually need to be defined when setting up the table but they are listed here for clarity.
I have also defined a GSI. This is derived from the Year attribute. This will group all the items by their Year, allowing me to query directly by year but also helping to chunk the entries which will make look-ups quicker and less expensive.
